Group Delay |
|
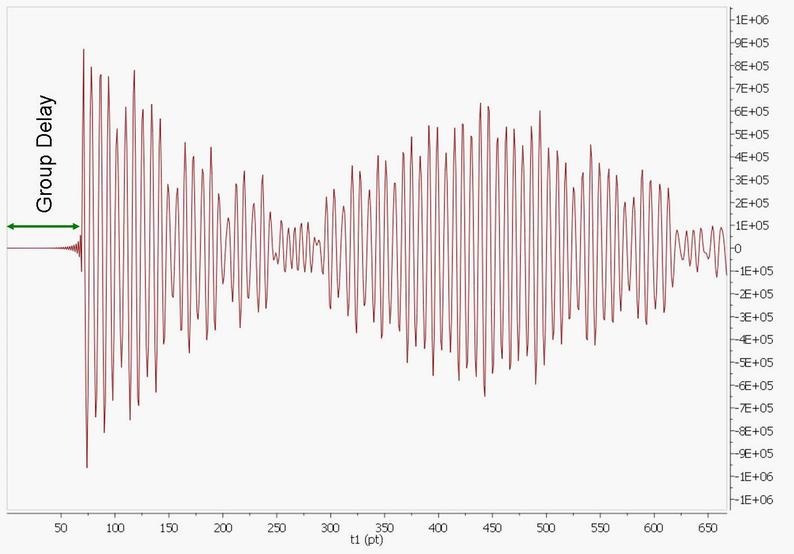
大多数 NMR 终于实现了完全数字化,现在通常采用几十兆赫的高频 ADC 采样率,并有不断提高采样频率的趋势。这种大幅度的超采样在简化前端电子设备方面具有明显的优势。由于随后的低频范围下变频是以数字方式完成的,因此理论上不会产生伪影,这也带来了许多其他好处。这包括完美的、无需校准的正交检测,以及大幅降低量化噪声。顺便说一句,这种技术在其他电子领域(军事、天文、音频......)也是常规技术;核磁共振只是其中的后来者。 不过,高频(HF)过采样本身也存在一些问题。从高频范围到音频范围的数字抽取以及上下文数字滤波(CIC 和 FIR 滤波器的组合)需要在硬件中正确实现,以便对用户完全透明。 不过,在布鲁克和捷尔波谱中可以观察到 FID 的死亡时间或群组延迟:开始时数值很小,然后在一些点(通常在 60-80 点之间)之后开始正常的 FID。
如果将一个普通的 FT 应用于该 FID,我们将得到一个基线上有大量摆动的频谱,类似于以频谱窗口中间为中心的 sinc 函数卷积。回顾傅立叶变换的时移定理,就可以解释这一点。该定理指出,如果时域信号移动 n 个点,频域频谱就相当于标准频谱(当 FID 没有移动时)乘以 exp(-i2*pi*w*n)。换句话说,我们在频谱中引入了非常大的一阶相位修正。例如,如果 FID 右移 60 个点(死亡时间 = 60 个点),f-频谱将出现 60 * 360 = 21600 度的一阶相位失真。
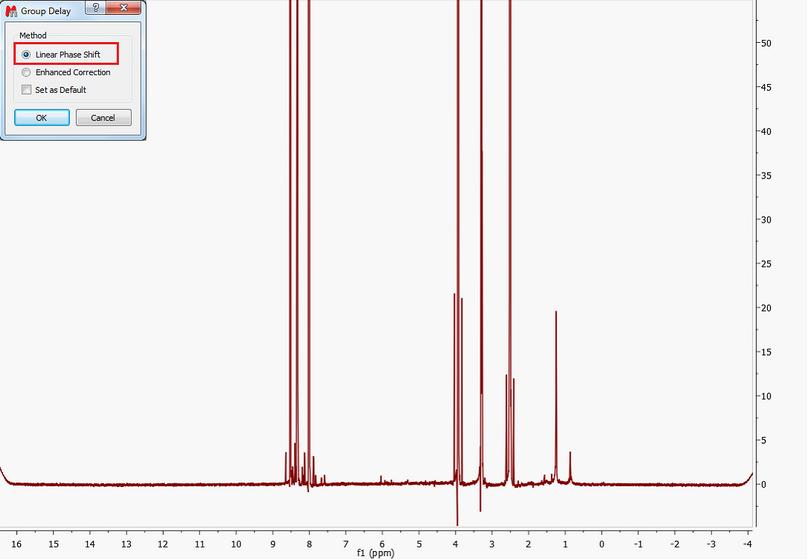
为了解决这个问题,Mnova 会读取群延迟的长度,以计算 FID 的实际起始点,从而应用所需的校正。 以前版本的 Mnova 会在 FT 之后应用线性相移,计算公式为群组延迟长度乘以 360 的乘积。这种方法的问题在于,生成的频谱通常会在频谱宽度的两个边缘出现所谓的微笑(见下图)。
从 6.1.0 版开始,Mnova 包含了一种新的校正算法(增强校正),可以生成正常的、物理上正确的 FID,从而在 f 域波谱中看不到微笑/褐色。
另请参阅 : http://nmr-analysis.blogspot.com/2010/05/bruker-smiles.html
|